Well, wish I had found this mini-book a bit earlier. But still, this is a really great read! It covers basically all aspects of a database system. What I like the most is that the author also gives industrial practice on each of the component.
I think a couple of things that the author points out that worth further invesigation, which I might do in the future:
- memory allocator and query processing of the PostgreSQL
- query optimizor of MySQL
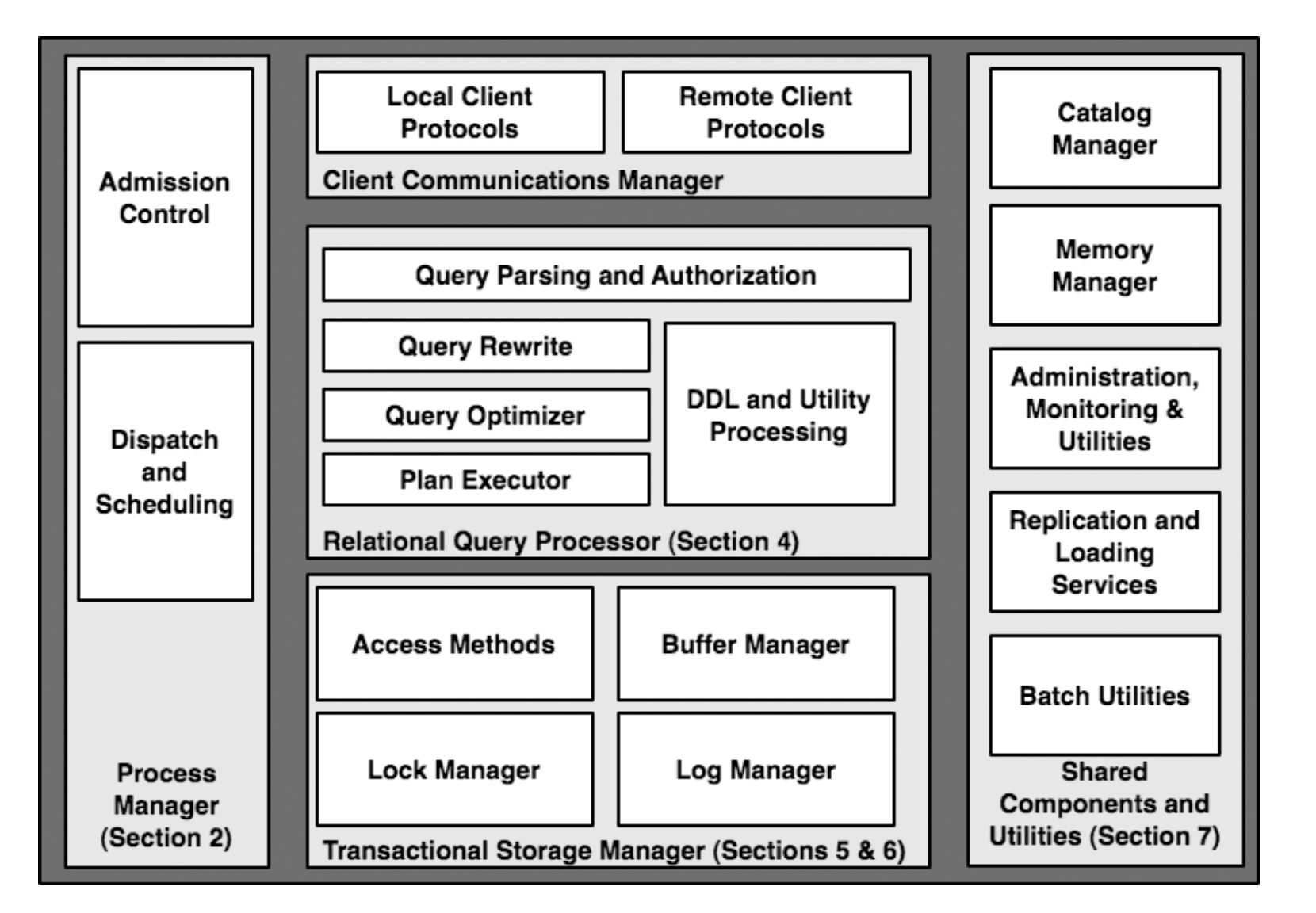
Processor Model
The processor model could be largely broken down to the following categories:
- Process-per-worker: a OS process for a DB worker (DB2, PostgreSQL, Oracle)
- Thread-per-worker:
- OS Thread-per-worker (MySQL)
- DBMS LWT per worker (the DB has its own user level threading library):
- It could be furthur broken done to whether the user thread is mapped to a process or to a OS thread.
- Process Pool (Oracle’s optional method)
- Thread Pool (SQL Server’s default)
The good take away is:
Most of the commercial DBs support more than 1 processor models, for various workloads and requirements.
Interesting process model (mostly active in research only):
Rather than having a worker for all the stages, have multiple workers for a single query. So it is more like a micro service/pipeline architecture. StagedDB is an academic example.
Query Processing
Could be further broken down to the below cases:
- Parsing : (aka, type checking, name checking), this could also be hooked up with the catalog to provide user-speicified types, which is how many systems extend the type systems in DB (like the structured XML type)
- Authrorization
- It is usually deferred to query plan generation so that security check is decoupled from query plan (allowing multiple users with different security rights to share query plans )
- Query rewrite:
-
View expansion: resolve view references into fully qualified table names and predicates. (This should is not applicable to materialized views, which are, materialized…)
- Constant evaluation:
1+1 = ? - Logical rewrite:
- Boolean logic relimination (
x > 1 && x < 0 => False): this is rather powerful semantics in fact. Since most of the time, the predicates are derived, so it is quite common some of the predicts could be evaluated to false, saving time for the DB. - transtive logic: add additional predicate so it might be useful for some indexes:
WHERE a = b AND b = 3will have the additional predicatea = 3, what if you happen to have a hash index ona?
- Boolean logic relimination (
- Semantic optimization:
- a foreigh key referenced column’s Table doesn’t have to be joined if it is just used as a join predicate.
- Example:
select A.x FROM A, B WHERE A.fk = B.k, whereB.kis a foreign key constrain onA.fkcould be simplyselect A.x FROM A
- Example:
- a foreigh key referenced column’s Table doesn’t have to be joined if it is just used as a join predicate.
-
Query Optimization
- Cascade (Top down) vs DP bottom up doesn’t have difference in the asymptotic bound in terms of the quality of a plan found
- optimizer usually works on
SELECT..FROM..WHEREtransformed query after pre-processing from query rewrite. - Plan space: traditionally only
left-deep(where the right-hand input is always the base table), now more oftenbushy(whre both sides could be nested). - Selectivity esimation: use of histograms ( histograms with inter-dependency are getting popular), as well as statistics.
- Columns’ historgrams are joined independently from each other previously
- TPC-DS benchmark now takes into dependency between different columns
- Parallel optimization: usually 2 phases, 1) optimize and output a single plan 2) executes that plan on multiple workers
Access methods
One of the main design choices is:
What if your underlying rows change its location, how does your index handle this?
-
secondary index / primary storage: references will need to change when the underlying row shifts
-
primary storage: like a B+ tree split will move tons of data
- secondary indexes stores the RIDs/physical references like pointers => lots of movements when the primary storage changes
- forwarding pointer => additional I/O to look at the real reference (DB2 does this)
- use primary key => lower performance but don’t need to move (Orcacle + SQL Server)
- Combo 1+3 => depends on the situations, use differnt (Oracle)
- DON’T allow primary storage as B+ index (Yay, DB2)
OLAP and Data warehousing
Some of changes that will affect the DB’s design:
- indexes less updates (no more B+tree, but Bit-indexes). The workload is basically, bulk insert once and scan multiple times
- Fast bulk load (loading large amount of data for data analysis)
- support of materialized view to avoid multiple joins on the fly
Storage
- raw disk access is no longer popular (filesystem overhead is pretty low, with techniques such as direct IO, concurrent IO, or using a large file)
Thanks but no, Double buffering is evil
- Correctness: DB might need to manage how data is flushed to the disk from the buffer
- Memory copy overhead: DB usually has been managing buffering by itself, so having duplicate buffers at OS level is wasteful.
- OS is blind: DB knows the access pattern and thus possible optimizations (such as pre-fetch B+ tree leave pages), but the OS only sees physical addresses.
Concurrency
Andy’s 721 class and 445 class both have good handouts on the theoretical concepts on serializbility and concurrency. Just something I cherry-picked from the paper that I wasn’t aware.
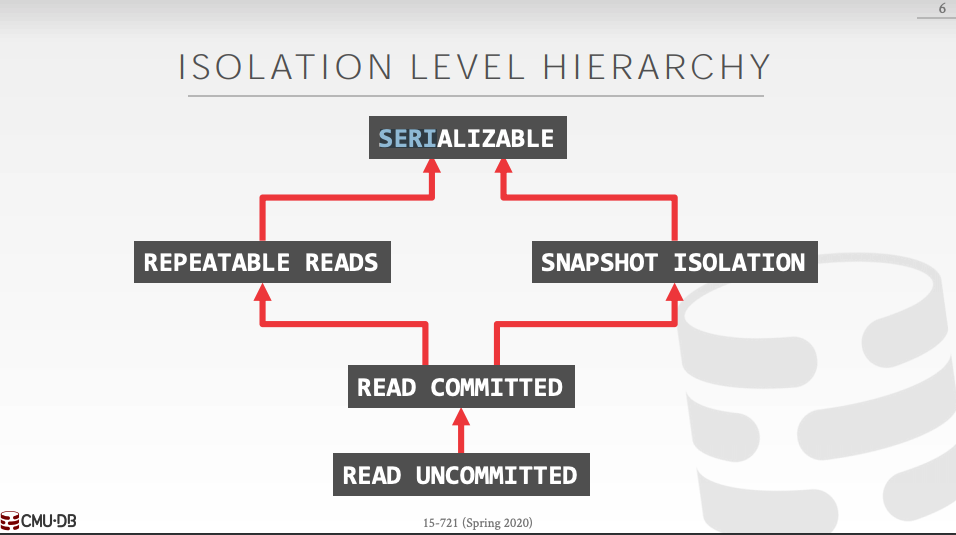
READ_COMMITTED:
- Lost Update: a concurrent txn might read and then modify based on a “dirty” read
CURSOR STABILITY:
- Solve the “lost update” issue of READ COMMITTED
- Hold READ locks in the cursor
B+Tree concurrency management:
- Concurrency control
- Yes, there is the crabbing (optimistic crabbing)
- There is also the Right-link schemes: each node now has a right-sibling reference. the basic idea is that if a split happens, the transaction should be able to realize that, and traverse through the right link to avoid incorrect paths. (PostgreSQL actually uses this!)
- Logging
- Structural changes to index actual don’t need to be logged
- why? for example, a split to a B+ tree node doesn’t have to be undo if the transaction aborts. Just let it be.
- So some of the physical oprerations ( and redo logs) could be marked as redo only
- Structural changes to index actual don’t need to be logged
- Next-key locking
- This is a cool solution to the phantom problem (well, still has its own caveats such as overlocking the surrogate range)
- For insert/update, it needs to acquire exclusive lock on the successor key!
- if insert into k = 5, and there is a select predicate on [3, 7]. Then this insert will be syncronized with the scan since the scan would have acquired share lock on the next-key of 5 (maybe within the scan range, maybe out of the scanning range)
Future Trends that will affect DB
Just copying some of the papers.
The many cores machines
One key challenge for parallel software architectures in the next decade arises from the desire to exploit the new generation of “many- core” architectures that are coming from the processor vendors. These devices will introduce a new hardware design point, with dozens, hun- dreds or even thousands of processing units on a single chip, com- municating via high-speed on-chip networks, but retaining many of the existing bottlenecks with respect to accessing off-chip memory and disk. This will result in new imbalances and bottlenecks in the memory path between disk and processors, which will almost certainly require DBMS architectures to be re-examined to meet the performance potential of the hardware.