1. [Best Paper] Opportunities for Optimism in Contended Main-Memory Multicore Transactions
Wow, this is cool:
We evaluate several concurrency control designs under varying contention and varying workloads, including TPC- C, and find that implementation choices unrelated to concurrency control may explain much of OCC’s previously-reported degra- dation. When these implementation choices are made sensibly, OCC performance does not collapse on high-contention TPC-C. We also present two optimization techniques, commit-time updates and timestamp splitting, that can dramatically improve the high- contention performance of both OCC and MVCC. Though these techniques are known, we apply them in a new context and high- light their potency: when combined, they lead to performance gains of 3.4× for MVCC and 3.6× for OCC in a TPC-C workload.
The CC protocol investigated:
OSTO(OCC variant)
- scalable timestamp allocator (like Silo)
- RCU style GC
MSTO(MVCC variant)
- Follows Cicada’s design
- Each version has a write timestamp (
wts), read timestamp (rts) and a state (PENDIGN/COMMIT/ABORT) - read-only TXNs always commit
- Commit protocol (I think this is just the standard?) :
- Bump the global wirte timestamp
- 1: append to all write versions chain of a
PENDINGversion (to lock it)- Abort when needed
- 2: checks read set
- 3: commit
The basis factors
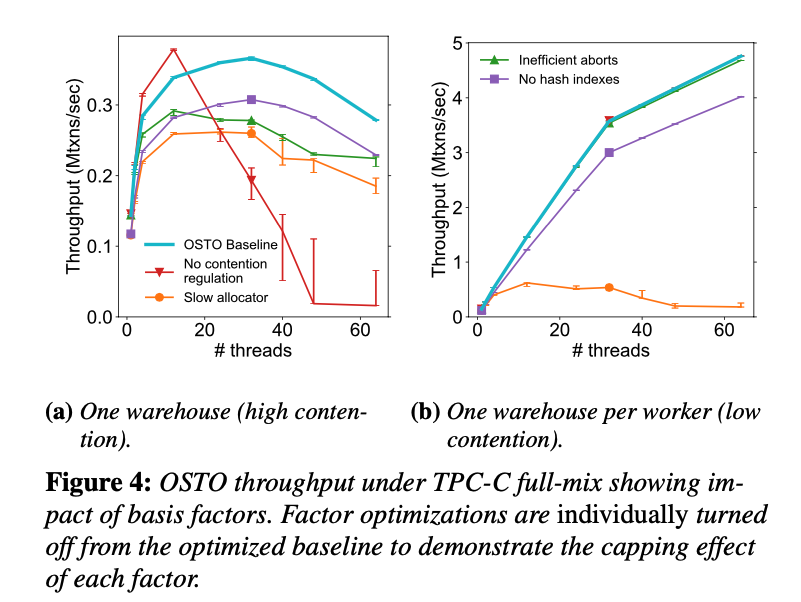
Contention regulation
- avoid cache line thrashing
- Exponential backoff
Memory Allocation
- the default glibc sucks
- bottleneck at low contention
- use a scalable memory allocator like rpmalloc
- 1.6x better at high contention
Abort Mechanism
- Exception style is bad (because global lock is acquired)
- Use checked-return is better
Index type
-
support hash table if can
-
support contention aware index:
-
sometimes, certain protection (like against phantoms) create additional conflict, which could be avoided given the workload or with the design of the index. Example of TPC-C workload (new order vs delivery):
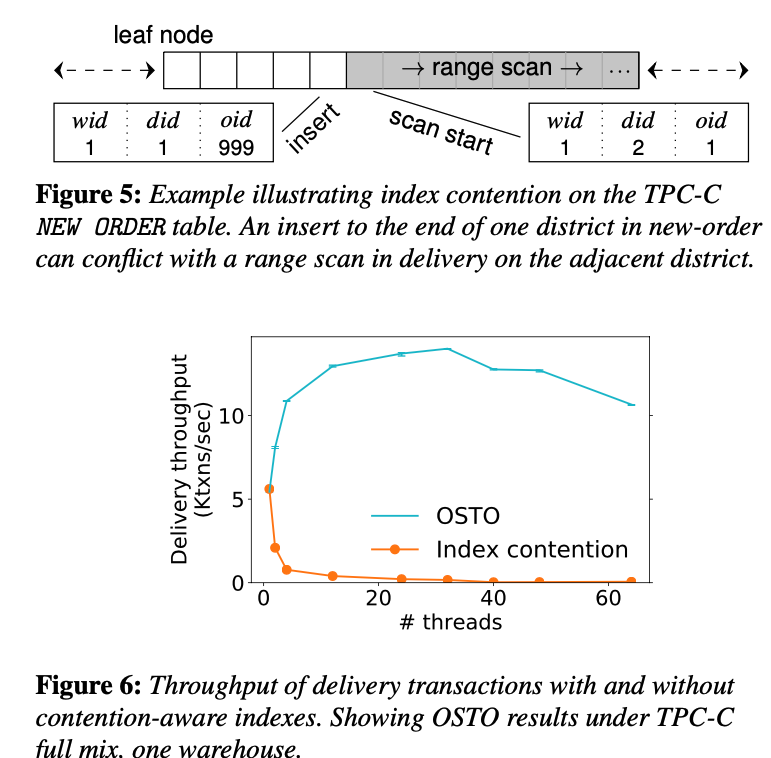
-
Commit time update:
- Some updates do not expose dependency, aka, its execution could be commutative with all operations after it. E.g.:
- Its value is not read after update as either data/control dependency
- These updates (usually, read-modify-write) could then be delayed to commit time
- Use a functional object (Updater) that captures the update logic, and only execute it during execution time.
Timestamp splitting
Not a really fancy idea though:
- have multiple (more than 1) timestamps for the record
- some of the fields are never modified (so they could always be read safely), and they don’t need to see frequent updates to the timestamp that might trigger conflict as a result of updates to other hot fields.
Pushing Data-Induced Predicates Through Joins in Big-Data Clusters
Video: https://www.youtube.com/watch?v=XrtYA1UadGs&ab_channel=VLDB2020
Motivation
-
predicate push-down has been proven to be a great techiqnue for query optimization, enabling partition elimination.
- Datatable is usually partiioned, with each partition having some sort of statistics (like min-max)
- Knowing the predicate, one can skip scanning some of the partitions by looking at the stats
-
However, if the predicate is not on a join column, the predicate could not be pushed down to the other table, for example:
-
1
SELECT * FROM A JOIN B ON A.y = B.y WHERE B.x > 1
- The predicate on
B.x> 1could not be pushed down toA(sucks if A is the larger table here especially)
-
Solution
- By looking at the stats of both tables A, B, we can find all paritions which have its
xfulfilling the predicate. - For all these paritions, we can then merge the stats of them on column
y, (the join column, which doesn’t have any predicate), and from the merged stats, one can derive a predicate now on the join column, which could be pushed down (or propogate to other parts of the query tree given relationaional algebra)
More
The paper talks about other crucial things like:
- How much could it filter?
- Well, this really depends, one of the example the paper gave could filter as much as 95% partitions.
- How to do it?
- This is hard, it also is coupled with query plan search scheduling
2. [Honorable Mention] MyRocks
Motivation:
-
B tree based (InnoDB) has issues:
- Large space fragmentation from the the B-index (up to 50% space usage)
- Limited compression (storage capacity becomes the bottleneck with new storage technology)
- Large write amplification on flash storage, which is bad.
- Space overhead for transactional handing( 13 byte for each row)
-
RocksDB is good because:
-
L-tree based buffer writes, and much better write amplification
LSM-tree is more effective because it avoids in-place updates to pages, which eventually caused page writes with small updates in UDB. Updates to a LSM-tree are batched and when they are written out, pages only contain updated entries, except for the last sorted run. When updates are finally applied to the last sorted run, lots of updates are already accumulated, so that a good percentage of page would be newly updated data.
-
Works well for compression. TXN related sequence number could be compressed away
-
RocksDB not neccessrily better:
-
On read performance:
We picked LSM-tree over B-Tree to save space at the expense of read performance. For read intensive databases where all data resides in memory, MyRocks was hardly better than InnoDB and the space savings benefit was minimal
MyRocks Design:
- RocksDB has more key comparisons => more sensitive to key comparison operatons
- reverse key scan is slow for many reasons => implement reverse key comparator
- stats estimation on a specific range for the optimizer costs CPU => skips esimation OR skips partially filled files to speed up.
- improve scan speed => prefix bloom filter (does this sorted file contain any key with matching prefix?)
- Too many tombstones in RocksDB because index update to the MyRocks will change keys in the RocksDB, which result in a Delete to the ROcksDB, that is implemented with tombstones (only remove at the last level of the LSM tree).
- => this means scan needs to process lots of tombstones entries as well
- => introduce
SimpleDeletewhich works under the assumption that no otherPUTwill happen to the same key (which is the case for the index update scenario)
3. TiDB
The HTAP world.
Key idea:
- Storage layer built on top of Raft protocol to ensure availability across multiple replicas. Its multi-Raft protocol extends the orignal Raft protocol with a few optimizations, such as -
- parallel log replication with logs appending at the leader
- decoupled apply thread from the main log handling thread
- optimized reads such as read index (heartbeat request from leader to followers to ensure the local to-be-read log implies it is still a leader), lease read (reads could be served automatically by the leader within the lease, and the follow not starting election during the lease), follower read( allows followers to serve reads by querying the leader if its local read is committed on the leader)
- regions split and merges
- Introduce a
learnernode that is responsible for converting row-based tuples into columnar storage for OLAP queries.
Row to Column
Each learner will :
- scan through the logs, compact it (ignore those rollback logs)
- decode row-based tuples (remove the timestamps and transactional information)
- convert rows into columns (with consult to the schemas)
To keep the schemas updated:
- periodic schema sycing (regular sync)
- on-deman syncing (compulsive sync): when the decoded tuple has different number of columns as the cached schema (or any anomalies)
Data structure for columnar stores - Delta Tree
It uses the Delta tree to store write and serve reads.
Write: appending to the delta stores simply add the new deltas into a delta file, and also append to a B+ tree index for the updates
Merge: the deltas need to be merged periodically (with the help of B+ tree)
Read: read the merged version
Comparison with LSM:
(on Sysbench of a select count query while data is being updated)
- better read latency
- higher write amplification
Comparison with MemSQL
The performance evaluation of TiDB is:
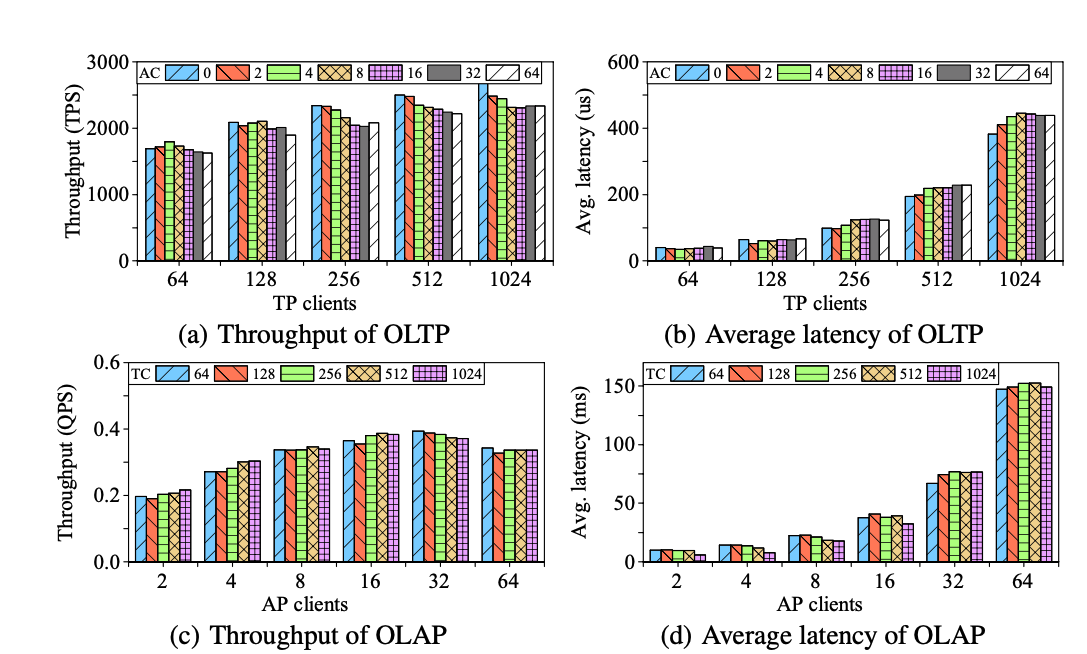
Which shows very little performance degradation of the transactional workload when more analytical clients are added. (a,b)
While for the MemSQL:
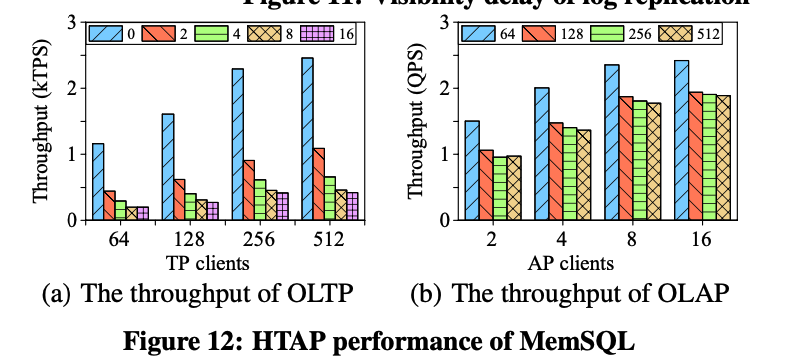
The degradation to the transactional processing throughput is really obvious with more AP added.
Notes:
One thing I did not really understand after reading the paper is: **Why use a B+ tree index though? ** Seems the Delta tree data structures could just be used with a hash index. Does it need range query?
4. DIAMetrics: Benchmarking Query Engines at Scale
It is: an architecture for benchmarking that is capable of generating indicative benchmark work- loads over production deployments, executing them, and measuring a system’s performance on that workload
Goals:
-
(a) deliver a general so- lution that is capable of benchmarking end-to-end a variety of query engines;
-
(b) support every step of the benchmark- ing life-cycle;
-
(c) provide insights with respect to sys- tem performance and efficiency. It is a one-stop tool for all benchmarking needs including complex tasks such as bench- mark generation, execution, and result visualization.
Previous Issues:
- the benchmark workload is statically defined
- the system being benchmarked assumes complete con- trol of the entire data management stack
Solution:
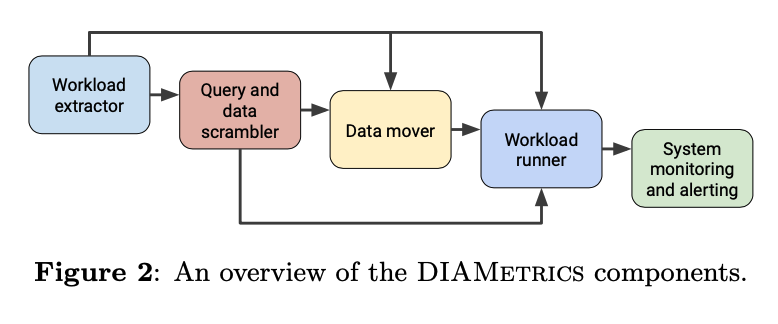
Wrokload Extractor: from query log generates features for each query, and the extractor will summarize them into some representative workloads (with “good” representative and “good” coverage of the original workload)
Scrambler: Anonymize the data with various tricks
Data Mover: Transform data into differnt formats for different query engines
Workload Runner: Handles scheduling and running of the workload with different configurations optios (benchmark coinfig, workload config)
My 5 cents:
I think the more interesting part of the paper is its Workload extractor , the rest seems rather standard practice. (The paper doesn’t seem to go into details how different components could be “pluggable” with use cases. So not sure how big the impact will be for agents other than Google iteself)